The Personal Landing Page
Posted by fedops in InfoManagement
It took me a while to come up with a coherent description of the questions that ultimately led to the solution I'm presenting in this post. Which in itself I think is quite straightforward. Bear with me here while I lay out the ideas:
- I like using bookmarks. Lots of people I know don't, but I have a rather lengthy list of them. Or more specifically, I used to have multiple lengthy lists on different systems, in different formats. And I thought "gee, wouldn't it be nice to have just one list accessible on all my devices, regardless of browser used".
- I keep finding new interesting web pages - while listening to podcasts, while watching a video, or while browsing the web on the couch. Things I would like to preserve for later reading, when I have more time or am back at the computer, or just generally keep as a reference for some future project or activity. My usual approach was to send them to myself as an email.
- As much as I like bookmarks, I'm terrible at organizing them. So it would be nice to have a simple method of sorting and arranging them by subject.
- Apart from the "read later" bookmarks I have places I visit every day, sometimes more than once -- news sites, Slashdot, the daily cartoon, the weather report. Those should be accessible easily.
- Lastly, I wanted a common landing page that I could set as my homepage for browsers when starting. It should have the bookmarks and common sites and weather report at a glance. And it shouldn't be publically available.
Now as alluded to in Ungoogling My Computing Part 2 I am generally accessing the Internet from all my devices through a set of Wireguard tunnels terminating on my VPS. Apart from running my filtering DNS server it also has a web server that is only accessible from the tunnels and 127.0.0.1, i.e. non-public.
I had seen Distrotube show his personalized landing page1 in a video and liked what I saw as a basis of getting all these ideas into one place.
The Landing Page
Starting with taking some clues from DT I downloaded the CSS and web page from his dotfiles repo and set about reworking both, eventually ending up with what's shown in the screenshot below.
I removed the seconds from the clock Javascript and instead of the Openweather API I used my CheckWX.com account to pull down the aviation weather METAR and TAF information for a close-by airport. This is the area marked (1).
The dark grey boxes marked (2) are my quick-access bookmarks, the ones I go to pretty much daily. The containers are a fixed height and scroll (as shown by the Reading and Reddit ones) if they are overfull. These bookmarks are hard-coded into the page's HTML code as they very rarely change.
A Javascript keyboard function pops up a fullscreen text box when the space bar is detected (3) and sends it off to my favorite search engine. This only works on desktop browsers, though an icon could be added for touchscreen use.
Following as (4) are the black containers which hold my "to read for later" URLs in categories. These can be updated dynamically, which we'll come to down below, and again every container scrolls as required. As indicated by (5) there are lots and lots of containers, more can be created on the fly, and the only requirement is that a name can only be used once.
This is the basic arrangement, and with suitable CSS it responds nicely to phones and tablets in landscape or portrait mode as well:
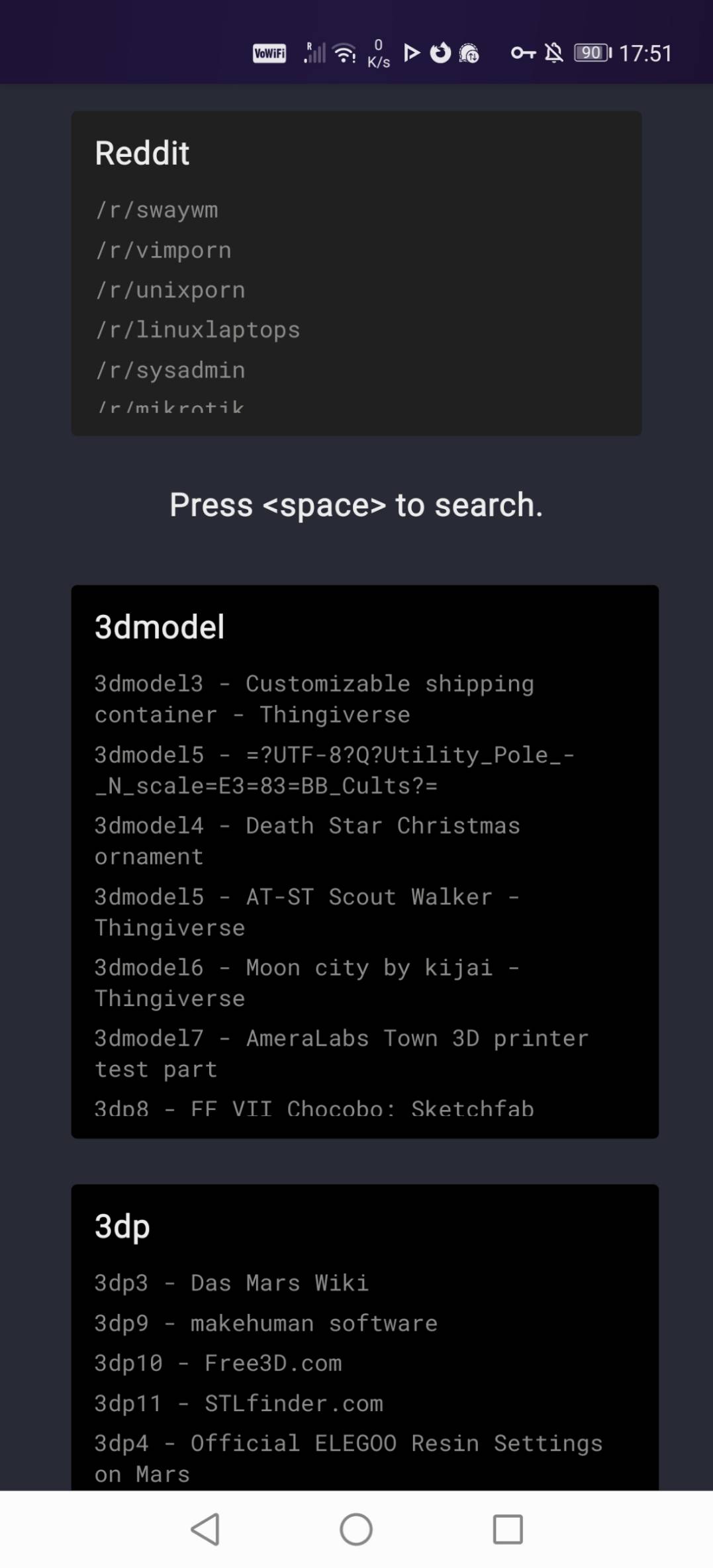
Managing the Bookmarks
So far so good but obviously laboriously hacking URLs into a bookmarks web page isn't going to work.
As mentioned what I used to do for years was emailing myself URLs for later consumption, thus plugging up my inbox. So why not set up an automated flow to take those mails, filter out the URLs and category names, and stick them into the page?
Filtering the Mail
I run my own mail system so doing that wasn't very difficult. First, set up a
virtual recipient to send mail to in /etc/postfix/virtual with the name of
"bookmrks" and point it to my normal user account.
Next, put procmail into the flow by calling it in ~/.forward:
~ $ cat .forward
"|IFS=' '&&exec /usr/bin/procmail -f-||exit 75
Finally, here are the two rules I appended to the end of my procmail
configuration file.
The first archives the mails coming to the bookmarks address in case something
goes wrong. The second calls a shell script called bmarks.sh
in my home's bin directory, piping the email into its stdin:
~ $ cat .procmailrc
[...]
:0 c:
* ^To: .*bookmrks@mymail.address
mail/bmarks
:0
* ^To: .*bookmrks@mymail.address
| $HOME/bin/bmarks.sh
Processing the Mail
The bmarks.sh script is reproduced at the end of this page. A few remarks:
The script expects mails to be in a specific format and it is not well equipped to handle deviations. The Subject: of the mail must contain the description for the link, and it should be fairly short to not fill up the containers too much.
The body of the mail must contain the URL to link to, then a space or tab, and then the category (container) name it should be put into. If the category doesn't exist it will get created. If the category is omitted the URL gets added to the category "uncategorized".
There's a bit of crusty logic included that will attempt to reassemble long URLs that got split over multiple lines. It works with the mail user agents I use (K9mail and Alpine), but your mileage may vary.
There shouldn't be any additional content in the body of the mail, although a properly separated signature (using two dashes and a space) will get cut off. If you share from Firefox Focus on Android to K9mail for example the format will be very close to what's needed automatically; only the category needs to be added.
Data Organization
The URL will then get added to a textfile with the name of the category, and it will be prepended with a running number, e.g "blog1" or "asm0". This makes it easier to find URLs when hand-editing the files.
Speaking of editing, the files are stored in the bookmarks directory as shown here:
~ $ cd /var/www/lighttpd/bmarks
/var/www/lighttpd/bmarks $ ll
total 376
-rw-r--r--. 1 user group 5004 Aug 6 2020 3dmodel.html
-rw-r--r-- 1 user group 1166 Dec 7 2020 3dp.html
-rw-r--r-- 1 user group 137 May 21 2021 asm.html
-rw-r--r-- 1 user group 117 Mar 31 2021 astro.html
-rw-r--r--. 1 user group 155 Jul 12 2020 blender.html
-rw-r--r-- 1 user group 1025 Jan 11 23:53 blogging.html
-rw-r--r-- 1 user group 462 Jan 30 2021 blogs.html
[...]
/var/www/lighttpd/bmarks $ cat asm.html
<a class="bookmark" href="http://kerseykyle.com/articles/ARM-assembly-hello-world" target="_blank">asm0 - ARM assembly hello world </a>
Sometimes links go dead, and to remove them is a matter of going into the respective category file and deleting the line. The numbering of entries will then have a hole but that doesn't really matter. Likewise, if you want to add or change an entry manually, it can be done simply by editing the file.
Putting It All Together
As you can see from the script below the actual web page is then created by outputting the top.html, looping over all existing category files, and finally appending the bottom.html.
Once that's done everything gets put into Git so there's a backup on the server
itself. That repo is set as remote for a repo on my home PC and every now and
then I will do a git pull to sync it down.
If I find an error I can also edit it on my local PC and git push changes up
to the VPS which will then incorporate them into the landing page the next time
it's built (i.e. the next time I email myself a link).
Considerations
The solution isn't bulletproof. For starters the script is somewhat simplistic.
Then there is also a gaping security hole in that if someone were able to guess the
email address they could flood the server with bogus entries until the disk
filled up. Some postfix filtering is put in place to prevent that.
The only dependency that is possibly not available right off the bat is the
procmail mail delivery agent (which includes formail); a very old-school
Unix utility package for programmatically handling mails. Being 30+ years old
and having been unmaintained for a significant time it has its security holes
and other problems (among which, a very arcane configuration language).
fdm would probably be a better alternative but my
.procmailrc is almost as old as procmail itself and I don't really feel like
rewriting that. Another case of "security by obscurity".
One might like a Python/Haskell/Forth/(insert your pet language here) version better. The shell version is nicely lightweight however, so it is well suited to running on small VPSes or Raspberry Pis.
Using basic text files instead of databases and other more advanced stuff has its pros, but also a few cons. For example exporting the bookmarks to something Firefox or other browsers could read as a bookmarks file would be easier if the data were better structured. But then if you want something like that and don't mind using third party services there are lots of options available.
Something very similar could be done via other transports, for example a chat bot instead of email. I like email though as I have it everywhere - I can and do submit bookmarks from my work PC for example, where there aren't any chat applications I would use.
The categories cannot be nested. Initial tests showed navigation especially on a phone would be really clumsy so I dropped the idea. I currently have 136 categories so there is some scrolling involved but so far it works. Every now and then some reorganization and trimming out of cruft is a good idea...
Conclusion
Syncing bookmarks seems to be an old hat, and there are multiple cloudy services for that. So is this worth it, especially since they're not actually synced to devices but just kept online on a server that needs to be paid for and maintained?
That obviously depends. What I like about this solution is a) it's under my own control, and b) I can change and extend it as I see fit. For example, integrating the inbound email filtering into a commercial service may or may not be possible.
I also like that the bookmarks are revision-controlled and automatically backed up so there's much less risk of losing anything.
There are more elegant personal landing page solutions made with a database backend and fancy Javascript frameworks. Not my cup of tea really -- the entire page including the Javascript is a mere 70 kB for currently around 400 bookmarks and can be proxied since on the delivery side it's a static page. That's a great size and you will hardly notice loading time even though the phone has to go online to fetch it.
Perhaps most importantly it was fun to build as well.
The bmarks.sh Script
Here's the script itself. For debugging purposes it can be run simply by piping
an email into it, e.g.: cat email.eml | ./bmarks.sh and inserting debug echo
commands as required for observing the operation.
Beware, it is not very error-tolerant!
#!/bin/bash
#
# bmarks.sh - bookmarks processor
#
# Usually links to check out webpages later are sent by email.
# This script processes such mails into a web page to not clogg up the
# inbox with dozens of these mails.
#
# The following format is expected:
# Subject: descriptive text of the bookmark
# Body: the URL, followed by whitespace and a category tag
#
# the URL is added to the file <category>.html
# all category file are then concatenated into index.html
# location of bmarks document directory
BMARKSDIR=/var/www/lighttpd/bmarks
TMPFILE=/tmp/$$.tmp
cat >$TMPFILE
umask 0022
SUBJECT=`formail -c -xSubject: <$TMPFILE | tr -d '\r'`
# grep out multi-line URLs. If this is empty we'll try again looking for a single-line URL
LINE=`cat $TMPFILE | grep -A5 '^http' | tr -d '\r' | grep -A1 '=$' | sed 's/=$//' | sed 's/=2E/\./g' | tr -d '\n' | awk '{print $1 " " $2}'`
# see if we got something, then go for single-line matching
if [ "X$LINE" == "X" ]
then echo got nothing
LINE=`cat $TMPFILE | grep '^http' | sed 's/=2E/\./g' | tr -d '\n' | awk '{print $1 " " $2}'`
fi
# split line into URL and CAT
URL=`echo $LINE | cut -f1 -d" "`
CAT=`echo $LINE | cut -f2 -d" " | tr -d '\r'`
# if there was no category keyword behind the URL, CAT and URL have the same content
# in that case, set CAT to be "uncategorized"
if [ "$CAT" == "$URL" ]
then CAT="uncategorized"
fi
# determine number of lines in CAT-file for sequence numbering
if [ -e ${BMARKSDIR}/${CAT}.html ]
then NUMLINES=`wc -l ${BMARKSDIR}/${CAT}.html | cut -f1 -d' '`
else NUMLINES=0
fi
# generate entry and append to category file
echo "<a class=\"bookmark\" href=\"${URL}\" target=\"_blank\">${CAT}${NUMLINES} - ${SUBJECT} </a>" >>"${BMARKSDIR}/${CAT}.html"
rm $TMPFILE
# generate overall bookmarks file
#
# remove old file
cd $BMARKSDIR
rm -f index.html
# generate preamble
cat ../resources/top.html >index
# loop over all sections
for i in *.html
do SECTION=`echo $i | sed 's/\.html//'`
echo " <div class=\"bookmark-set\">" >>index
echo " <div class=\"bookmark-title\"> ${SECTION} </div>" >>index
echo " <div class="bookmark-inner-container">" >>index
cat $i >>index
echo " </div>" >>index
echo " </div>" >>index
done
# generate closing tags
cat ../resources/bottom.html >>index
mv index index.html
# check into Git
git add bmarks
git pull
git commit -am "update ${CAT}"
git push origin master
Addendum: I have added the fragments mentioned above to my repository. Feel free to use them to get your own solution started.
-
his original, hand-crafted one. I believe he has since moved to a more elaborate setup. ↩