Note Taking and Searching
Posted by fedops in InfoManagement
I previously wrote about my note taking/information management process here and here. Quite a lot has changed so it's time for a re-revisit.
As noted I found the one-massive-file Wiki approach limiting, especially since it wasn't easily accessible from the command line which is where I spend most of my time. Then the Joplin file sync approach was better, but still far from perfect.
Information wants to be free
In the 1990s I had kept my notes, one file per thought, in a hierarchy of text files. A lot of the information before the web was a thing actually came from mailing lists and Usenet postings. So each file had a Usenet-style header with Date:, Subject:, and From: lines, which as often as not was just retained from the original post. I used plain and simple grep to search through them. 30 years later I am still a fan of that, and I wanted it back in a slightly modernized form.
With the current developments around Documentation-as-Code, that feels more important and achievable than ever. A simple text editor should be enough to write and read things. I also wanted the text files to be Markdown because that's the new fanciness -- and it's also very useful and trivial to change 10 years down the road when the new fanciness arrives. Finally though, it would be nice if one could also save a screenshot image or a PDF file and essentially use it the same way.
So the general structure looks like this:
├── linux
│ ├── ...
│ ├── os
│ │ ├── ...
│ │ ├── dnf.md
│ │ ├── flatpak.md
│ │ ├── nmcli.md
│ │ ├── sudo.md
│ │ ├── systemd.md
│ │ ├── vim.md
│ │ ├── ...
│ │ ├── wifi.md
│ │ └── yum.md
│ └── software
│ ├── alpine.md
│ ├── audio.md
│ ├── blog.md
│ ├── chezmoi.md
...
...
The Parts
The two things that finally made me rethink and change the process was me becoming ware of ripgrep and fzf, the fuzzy finder. Ripgrep recursively searches directory hierarchies for regexes. It combines nicely with fzf to present previews of the results in a human-digestible form and make them selectable. Fuzzyfinder is so immensely useful for all kinds of things, it's mindboggling. The combination of the two is a really great match.
What's even better is rga - ripgrep advanced which extends the ripgrep idea to also make PDFs, Jpegs, SQlite databases, and even those pesky binary office documents searchable. The icing on the cake then is bat - a cat clone with wings which is a syntax-aware terminal file viewer that renders Markdown and other languages in an easy to read fashion.
Putting it all together
With these programs available and installed, either from distribution
packages or via a git clone, a little bit of shell script glues everything
together as my notegrep command:
#!/bin/bash
#
# ripgrep recursively through notes
#
# uses rga: https://github.com/phiresky/ripgrep-all
NOTESDIR=~/Documents/notes
RG_PREFIX="rga --files-with-matches"
cd ${NOTESDIR}
file="$(
FZF_DEFAULT_COMMAND="$RG_PREFIX '$1'" \
fzf --sort --preview="[[ ! -z {} ]] && rga --pretty --context 5 {q} {}" \
--phony -q "$1" \
--bind "change:reload:$RG_PREFIX {q}" \
--preview-window="70%:wrap"
)" &&
echo "opening $file" &&
bat --theme=TwoDark "$file"
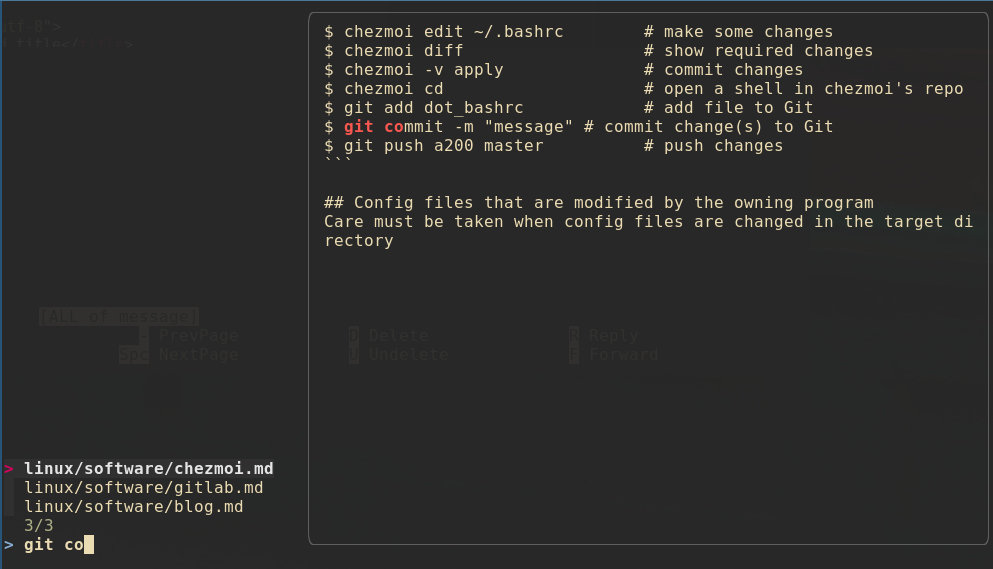
So if I now type notegrep git and press return, then fzf presents a list of all
files with the word "git" in it, previewing the first one. In the screenshot
below I have continued typing Space-co and the display narrows down to just
those three files, again previewing one. Simply pressing Return at this point
opens the selected file in bat, while hitting Esc terminates fzf and returns
to the terminal prompt.
With the data being available as Markdown it would be simple to also feed the
whole lot into a static site generator like
pelican to produce
navigable HTML content, or using e.g. pandoc to create a well-structured PDF
document. Most of the time though, a simple ASCII presentation of the content of
a note is all that's needed.
I've used this setup for over a year now and I really like it. Very few moving parts, no databases or fancy editors, just the text mam...